Artificial Intelligence In Healthcare
Is synthetic data the future for improving medical diagnosis?
 Photo by National Cancer Institute on Unsplash
Photo by National Cancer Institute on UnsplashAccording to the World Health Organization, skin cancer represents approximately one third of every diagnosed cancer, reaching over 3 million cases over the world, annually. Similar to other types of cancer, though, early diagnosis is key to a good outcome, and computer-aided diagnosis has shown great promise in being able to recognise melanomas. Neural networks can be applied to distinguish between melanoma and non-melanoma cases in a few seconds, which makes it a great help to the diagnosing physician. But deep learning (DL) based approaches need a large amount of annotated data to perform well. In addition, the use of healthcare data in the development of DL models is associated with challenges relating to personal data and regulatory issues. Patient data cannot be freely shared and is therefore limited in its usefulness for creating AI solutions. All of these issues can be addressed using different methods, showing the potential of artificial data for such use cases.
The Potential of Synthetic Data in Healthcare
In order to tap into the potential of AI for health, we need to address challenges such as data confidentiality and data access. Synthetic data and generative models could aid the research community in addressing these challenges while advancing the use of AI in healthcare. In this way we can also share data in order to work together with other institutions, facilitating reproducibility of different models and research projects, hence accelerating the application of AI across different hospitals.
Another potential benefit is that data scientists can augment the amount of data and balance the datasets to improve the robustness and accuracy of classification networks which are aimed to assist doctors in diagnosis. This is particularly interesting for studying rare diseases where collecting data is much harder since the cases are more limited. In this way researchers could also generate data for underrepresented patient subgroups. This is helpful in reducing biases in the dataset that make the algorithms biased towards a specific type of patients and thus less robust. Unfortunately, it is not a common practice to have a large enough (and additionally easily accessible) dataset for healthcare use cases. But still there exist some datasets good enough to start with.
International Skin Imaging Collaboration
Our experiments were started with the open-source (hence, previously anonymized and legally shared) International Skin Imaging Collaboration (ISIC) 2020 database. This dataset consists of more than 33 thousands dermoscopic training images of unique benign and malignant skin lesions from over 2 thousands patients. The dataset was created for the SIIM-ISIC Melanoma Classification Challenge hosted in Kaggle during the Summer of 2020.
In the beginning of your journey with new data it is extremely important to know its statistics. This could be really helpful during evaluation of the results, so that you can draw the most appropriate conclusions. Sometimes a misclassification or other errors are caused by the imbalance or even erroneous annotations. In case of ISIC 2020 we have access to two classes of images (melanoma and nonmelanoma) and tabular data with characteristics such as sex, age, anatomical sites and width/height of images and moles themselves. Let’s try to examine its main statistics.
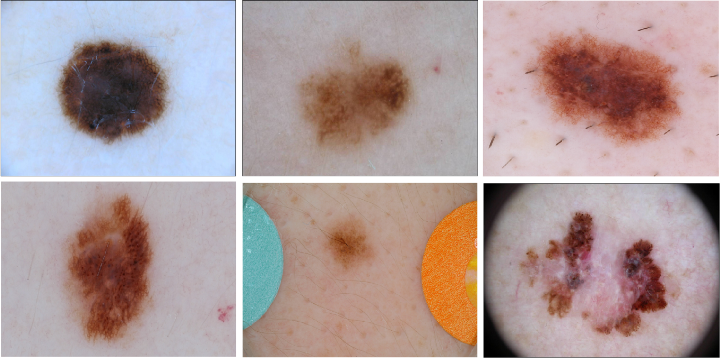
Example of malignant and benign melanoma from ISIC 2016 dataset. Observed moles can have different sizes and colors. some of them are a little hairy. Image by ISIC Challenge Dataset.
Understanding the modelling challenges
When it comes to images, ISIC 2020 has pictures of different colors and sizes, with or without a scale drawn on the patients’ bodies, and some moles are seen through the lens of dermoscopy. This could have a meaningful impact on the outcome of the models, especially when we want to train a neural network to generate additional skin samples to produce more images. The investigation of both the training and test subsets of the dataset can help us measure whether we can make similar observations in both subsets. This will allow us to ensure that we train and test models on data with the same characteristics, which will help prevent misdiagnosis in the future.
On the other hand, examination of the provided metadata is useful to understand the population where the data stem from: for example, what is the age distribution of the patients in the dataset and are there are sex differences in the prevalence of the target (i.e. having melanoma). We can expect some missing values in the metadata, which should be filled in first with some fixed or most frequent values.
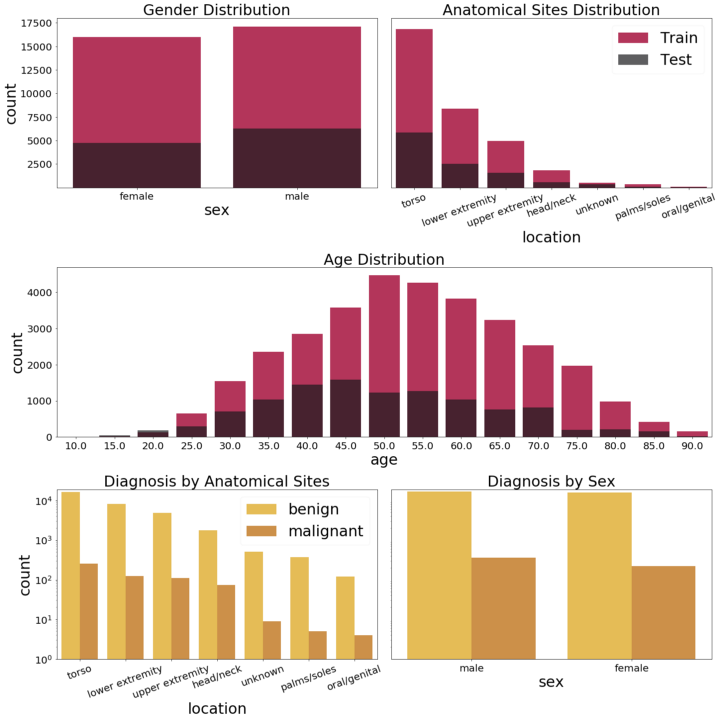
Basics statistics about ISIC2020 dataset distributions. Note that the scales shown in the lower histograms are logarithmic — due to the very small number of malignant melanoma samples, presenting the data on a linear scale makes the bars almost invisible. Image by authors.
As we can observe, even though the dataset is quite large, it has several drawbacks. The main one is the fact that it is highly unbalanced, i.e. there are only approximately 2% of melanomas in the whole dataset and, moreover, the malignant images are predominantly male. The images have different resolutions, different quality and almost all of them belong to fair-skinned people. In this case, as mentioned above, synthetic data can come to the rescue.
Information-Driven Healthcare in Sweden
In our particular project at Sahlgrenska University Hospital, we are focusing on generation of synthetic dataset of skin lesions and diseases, such as melanoma. Using synthetic data can facilitate the work tremendously since we don’t have to care about privacy issues for sharing data between the different hospitals — partially because the possibility of data leakage still exists.
Another use case is a Decentralized AI Project in which Sahlgrenska University Hospital, AI Sweden and Region Halland are involved. With decentralized AI we aim to achieve collaboration and orchestration among hospitals and institutions while preserving patient data confidentiality. This can be done by using Federated Learning or Swarm Learning/Peer to peer [3, 4]. Essentially, this means training AI models in each institution and then sharing the insights (model parameters), instead of data, in order to build a more accurate model together. With generated synthetic data we can work more easily on a first implementation as a Proof of Concept (PoC) or Proof of Value (PoV).
Furthermore, the example of skin cancer diagnoses presented here is just a toy example (PoC in fact) of the use of artificial intelligence in healthcare. This study can be easily transferable to other use cases such as rare diseases like brain tumors. In such cases, data is hardly accessible and generation of artificial realistic samples can be helpful for a good diagnosis. And as machine learning models are trained using mass amounts of data the synthetic one can be a good choice to enable data sharing, and ensure medical research reproducibility.
Sylwia Majchrowska
Postdoc Research Fellow
Unleashing the power of AI to solve real-world challenges, an AI Enthusiast and Problem Solver.