How scientists use artificial intelligence to identify garbage?
Brief review of Detect Waste in Pomerania project
 New year provides a great opportunity to implement environmentally friendly solutions on a larger scale.
New year provides a great opportunity to implement environmentally friendly solutions on a larger scale.Trash is everywhere. Left uncollected, it often ends up harming the environment. To clean it up efficiently, we need to learn how to recycle it, and localize the places that are most contaminated. But before we move on to more decisive actions, we must realize what obstacles lie ahead.
The most difficult challenge is the lack of clearly defined, uniform guidelines regarding the principles of segregation. During our project, we realized that there is no single principled approach explaining the correct segregation of waste. For example the “chips package” discussed with our annotators team, by someone can be treated as waste belonging to the metals and plastic group, and by others as waste belonging to the non-recyclable group, due to the variety of types of plastic material (not all are recyclable) it is made of.

On the other hand, waste is commonly found in a wide variety of environments. Both indoor and outdoor environments such as household, office, road and pavement scenes, and even under water. This diversity must be well represented in the training set presented to the detector to obtain good results. And at this point we come back to the problem of the lack of access to large amounts of annotated data that is necessary in the machine learning process.
Of course, litter detection is such a common problem that these issues were already faced by many researchers, and some solutions were already proposed. In this post I will describe how scientists have approached the problem of locating and recognizing the type of garbage from images using artificial intelligence.
First step - classification
The most frequently quoted work, that started it all, is a student project. Yang and Thung from Stanford University collected the TrashNet dataset of 2500 images of single pieces of waste, and classified them into six classes consisting of glass, paper, metal, plastic, cardboard, and trash. The dataset is well balanced (almost ~500 images per category), but consists of photographs of one piece of garbage taken only on a white background. Authors compared the performance of deep models, and pointed out that the use of convolution neural networks (CNN) for classification of trash into various recycling categories was possible, but it would require collecting a larger and good quality data.
In next approaches scientists tried to train variety CNNs to propose the best training scenario. They, for example, dealt with some augmentation methods (like rotation and flipping) or recent optimization algorithms (like Adam and Adadelta optimizers). In the end the satisfactory results (accuracy above 95%) were obtained, confirming the possibility of using artificial intelligence to carry out the task of segregating garbage. At the same time the need to enlarge the publicly available dataset again was emphasized.

Next step - localization
New annotated dataset was introduced in 2016 and called Garbage In Images (GINI). Collection was created by using Bing Image Search API. The authors of this GINI dataset proposed GrabNet architecture, which on the GINI Dataset reached an accuracy of 87.69% for the task of the detection of garbage - localization of all trash in the image by scratching a bounding polygon around it. However, GarbNet provided no details about types of waste present in the image, and produced wrong predictions for waste seen in the distance. Another approach to locate the garbage (one class) in an image resulted in the fusion of the garbage dataset with several other datasets of common objects in urban scenes. Authors reached an accuracy of 89%. However, the model produced false positives when in an image there were also other objects in addition to waste. A different end-to-end approach has been proposed for the detection and classification of garbage underwater. The four network architectures selected for this project were chosen from the most popular and successful object detection networks. The best model (Faster RCNN with Inceptionv2 backbone) achieved accuracy of 81%, but faltered in terms of inference time.

Recent achievements in waste detection task
TACO dataset, which we finally decided to use, can be used in methods that involve a segmentation component - we know the exact object boundary, not only the bounding box. Best accuracy for the TACO in one class instance segmentation task was around 20%. The big challenges are the large imbalance of the dataset itself, diverse outdoor backgrounds, and a large variety within a single class label (more about TACO dataset statistics you can find in our previous post). Chinese scientists decided to face this. They were solving a problem of two-class (waste vs. background) semantic segmentation task. The task of semantic segmentation relies on assignment of each pixel of the image to the appropriate category. This approach allowed them to get high quality segmentation results with 96.07% mean Pixel Precision on TACO dataset and 97.14% for MJU-Waste dataset, which they created from indoor photos of waste. Recently for semantic segmentation tasks, a novel dataset TrashCan to detect garbage underwater was also created. In this case, the simultaneous location and classification of objects also fared much worse.

Detect Waste in Pomerania project
In the Detect Waste in Pomerania project we intended to base our research on TACO dataset - an open image dataset of waste in the environment. We converted TACO categories to detect waste categories according to the obligatory segregation rules of the city of Gdańsk. Additionally, around 3k images were tagged by our partner Epinote with bounding boxes. In this way, we started with waste detection performed for 6 classes - paper, glass, metal and plastic, bio, non-recyclable, and other - on an extended TACO dataset (almost 4.5k images).
Unfortunately, there are types of waste that do not fall into any of above-mentioned categories - very crowded photos with garbage obscured by various objects, where it was not possible to tag individual garbage, and trash that could not be clearly identified due to their state of degradation. We have created another category for it - “unknown”.

Simplifying the detection task
We mainly conducted our experiments on an EfficientDet network, written in PyTorch. EfficientDet is a family of object detection models that came out of the Google Brain team. It is based on the EfficientNet paper, which achieves one of the best performances on the image classification task. In our case EffcientDet-D2 gave us the best possible results. Smaller architectures got lower scores, whereas bigger ones quickly overfitted. We hypothesize this is because the dataset itself is small (roughly 4.5k images) and highly imbalanced.
| model\metric | mAP@0.5 | APother | APplastic&metal | APbio | APnon-recyclable | APglass | APpaper | APunknown |
|---|---|---|---|---|---|---|---|---|
| Efficientdet-D2 | 18.78 | 0.61 | 50.89 | 0.00 | 15.03 | 25.11 | 22.39 | 17.53 |
Existing datasets do not provide a large number of object classes with sufficient training data. In addition, as we managed to find out, differentiating waste instances under a single class label is also challenging. In order to use all data from public datasets (some of them was mentioned above), we decided to perform a detection task on a combined set of roughly 36k images from various backgrounds; namely indoor, outside, underwater enviroments. We also tested other architectures, like DETR and Mask R-CNN.
| model\metric | iouType | AP@0.5 |
|---|---|---|
| Efficientdet-D2 | bbox | 74.81 |
| Efficientdet-D3 | bbox | 74.53 |
| DETR-R50 | bbox | 50.68 |
| DETR-R50 | segm | 54.80 |
| Mask R-CNN (ResNet50) | segm | 23.05 |
| Mask R-CNN (ResNeXt101 64x4d) | segm | 24.70 |
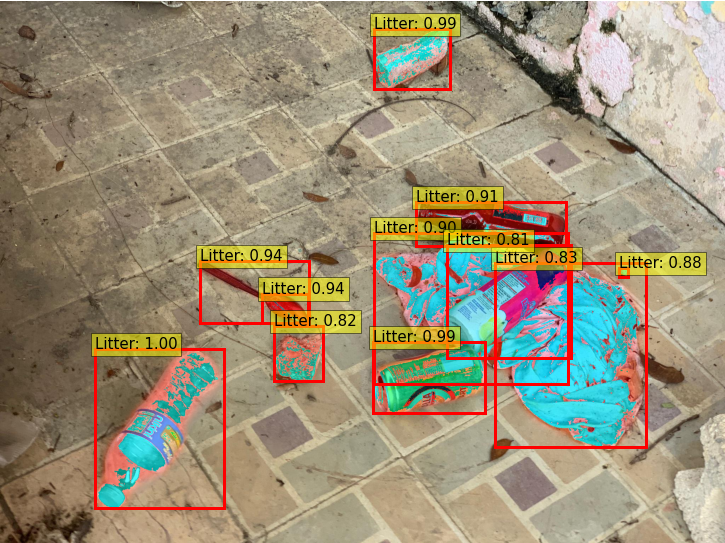
From detection to classification
In this part of our research we focused on assigning garbage to the appropriate category. Detect waste categories were chosen according to the segregation rules of the city of Gdańsk. We were working with the following seven categories:
- metals and plastic: metal and plastic rubbish such as beverage cans, beverage bottles, plastic shards, plastic food packaging, or plastic straws;
- paper: paper items such as receipts, food packaging, newspapers, or cartons;
- glass: glass objects such as glass bottles, jars, or broken glass;
- bio: food waste such as fruit, vegetables, herbs;
- non-recyclable: non-recyclable rubbish such as disposable diapers, pieces of string, polystyrene packaging, polystyrene elements, blankets, clothing, or used paper cups;
- other: construction and demolition, large-size waste (e.g. tires), used electronics and household appliances, batteries, paint and varnish cans, or expired medicines;
- unknown: hard to recognize, obscured objects.
Additionally we have added the eight class: background, because it was necessary to limit the amount of false positives coming out from our detector.
- background: area without any litter, e.g. a sidewalk, a forest path, a lawn.
We used cut the litter instannces from the detection dataset - the annotated bounding boxes from our dataset can be also used as an input to the classifier - and some additional data from TrashNet and waste pictures datasets. We also scraped remaining data from the web - to avoid huge data imbalance we have used Google Images Download to search and collect many images with bio and other waste
This way we have gathered thousands of images that could be used for our task. However, we still had in mind that OpenLitterMap offers an enormous number of litter images to use (~100k images). This is when we started to think about semi-supervised learning.
Semi-supervised learning uses both labelled and unlabelled data to improve the training process. One of the methods is pseudo-labelling which is the process of using the model to predict labels for unlabelled data.
For classification task we used the EfficientNet-B2 network, which also is a backbone in our best waste detector - EfficientDet-D2. Additionally, we used multiple data augmentation techniques, which are very important in the waste classification task. The instances of litter can assume different appearances depending on the environment in which they are located - in home, underwater or outside. Here, we applied some methods implemented in the albumentations library.
After running 20 epochs of training with a 0.0001 learning rate and batch size of 16 on our neural network with a almost 3/1 train/test split, we achieved a testing accuracy of 73.02% (and 86.67% training accuracy). In the experiment the vast majority of our samples from the test subset were classified correctly.
Finally, we tested the classifier in combination with the detector on various video files to see how it behaved in real-world-scenario. Very good results were found in case of localization, the network was able to detect the majority of litter in non crowded images. Unfortunately their classification appears highly unstable - the same object in different frames was classified to various classes.

Conclusions
During the process of developing these models, our team has looked through thousands of images that are just full of piles of trash: in home, in the natural environment, on the street, in the sea, in countries around the world. We learned how determine the approximate location of the abandoned garbage in the image.
On the other hand, pseudo-labeling allowed us to utilize unlabeled data from OpenLitterMap while training classifiers. However this technique gave only a slight performance bust in case of litter detection tasks. This can be related to high imbalance and small amounts of labeled data, to which we had access, especially in case of bio or other classes. In the future the main goal will be to increase the performance of classification by balancing the number of images in the dataset.
Did you find this post helpful? Check for more at our project site.
Sylwia Majchrowska
Postdoc Research Fellow
Unleashing the power of AI to solve real-world challenges, an AI Enthusiast and Problem Solver.